

Что такое парсинг и бот-системы/сети?
Парсинг это получение данных в автоматическом режиме с сайта-донора. По сути этим занимаются или отдельные парсеры, или целые бот-системы. К примеру, гугл использует, как и другие поисковики целую свою сеть ботов. Часть из них получает ссылки, часть переходит по ним и анализирует содержимое. Задачи по парсингу встречаются чаще чем хотелось бы.
За долгое время в веб-разработке пришлось мне поучаствовать и в создании крупной бот-системы, имитирующей действия людей в одной из профессиональных социальных сетей, так и создавать парсеры.
Для себя я разделил их на два вида:
- Ситуативные - один раз использовали и может периодически запускаем
- Постоянно работающие
Ситуативные нужны тогда когда данные с одного сайта нужно скачать единожды и возможно время от времени обновлять. Для таких целей иногда используют Python. Но как по мне это трудоемкий процесс, хоть и дешевле. Куда более мощный инструмент и намного удобнее, это ZennoPoster. В большинстве ситуаций для меня это инструмент парсинга №1. Дальше объясню почему.
ZennoPoster - для ситуативного парсинга
Незаметность/Неотличимость от обычных пользователей
Как вы можете понять по названию, речь об обходе капчи и других систем идентификации автоматики. Строя бот-систему мы изучали много разных вариантов как скрыть пользователя, сделать его уникальным и наоборот, подать как обычного рядового пользователя. Последний вариант наиболее успешен, ведь уникальный пользователь изначально подпадает под подозрения автоматики. В Зенопостере вы можете визуальными средствами задать профиль, а сам инструмент построен на базе обычного браузера, с JavaScript и прочим. Выявить такого пользователя уже сложнее. Подключение прокси штука не сложная, но сами по себе они вас больше раскрывают чем, прячут. Вполне логично что кроме вас купить пакет прокси могут и сотрудники корпорации. В итоге одним или несколькими платежами палится вся сеть прокси. Не можете создать свои прокси, тогда покупные это вариант лишь для самых простых случаев. Но мы отвлеклись.
Гибкость и расширяемость
В нашей системе мы использовали клиент-серверную архитектуру, где раздачей задач и цепочек действий занимался сервер. Бот же выполнял необходимый набор действий. При этом куки можно было сохранить вместе с профилем пользователя и снова его загрузить. Все это прогревало профиль пользователя и на целевой сайт он мог идти уже не с пустым браузером. Расширяемость же в том, что кроме работы со списками, таблицами, базами данных и прочими встроенными инструментами, вам доступно расширение языком C# и подключением внешних библиотек. Так, мы использовали в другом случае OCR(систему распознавания текста на картинках), для распознавания номеров.
Стоимость
Тут скорее минус, так как он платный и стоит немало. Но если работать профессионально оно того стоит. А если попасть на скидки, которые бывают каждые пол года, то можно снизить его стоимость до 50%. С какой версии начинать, зависит от вас. Для разовых случаев хватит и Project Maker-а, который нужен для создания и отладки шаблона. Можно даже не запускать сам ZennoPoster. Когда вам нужно уже многопоточный режим, тогда уже стоит брать более дорогие версии.
Документация и примеры
Есть форум, есть официальная документация и несколько примеров. В целом обучение не очень сложное. А кроме парсинга можно автоматизировать много других задач в сети.
Результат можно спокойно залить csv файлом в целевую систему, создав там нехитрый импорт. ZennoPoster можно купить по ссылке.
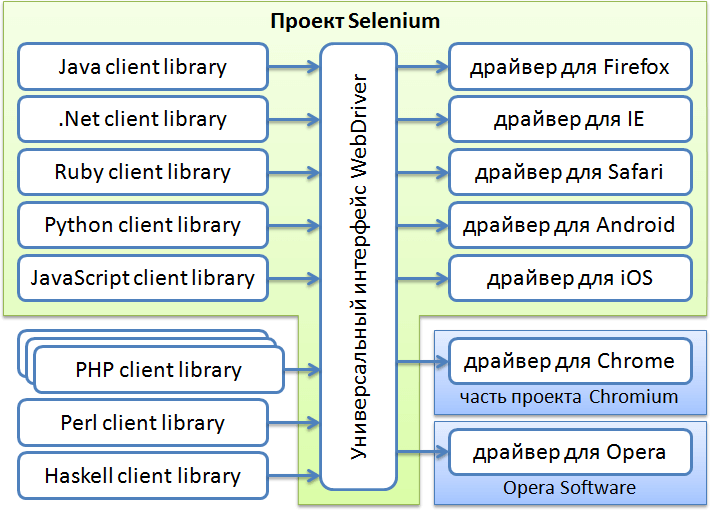
Для постоянного парсинга - построение более сложной системы.
Такие системы уже более сложные и хоть можно использовать зенопостер, но в целом предпочтительнее использовать уже другой подход. Использовать Selenium и другие надстройки над движком браузера, прогонять страницы и парсить результаты. Системы защиты от таких парсеров разные, вплоть до динамического изменения классов и названий на странице как в HTML, так и в CSS, и JS. Используются капчи, проверка юзер-агента, айпи адресов и вплоть до косвенных признаков. К примеру маловероятно что используя Google DNS указывающий что вы из Европы, вы будете подозрительно выглядеть с IP адресом из США. При этом использование TOR автоматом делает вас подозрительным для практически всех систем.
Такие парсеры уже делают на Python, PHP, NodeJS с добавлением предназначенных для этого библиотек. Получение элементов происходит по XPath, Query Selector-у и регулярным выражениям для поиска подходящих ключевых слов на странице.
Разработка такого парсера дороже, поддержание сложнее. Нужны системы мониторинга и анализа, на тот случай если данные перестали добавляться в систему, а парсер забуксовал и сыплет ошибками.



Отзывы
Пока нет комментариев
Для того чтобы оставить комментарий, авторизуйтесь.